

用C++开发一个图片爬虫 Ⅲ :URL预处理 【咕咕】
封面图片来自网络,如有侵权将删除。
前言
上一节说这节介绍WinHTTP,现在好像鸽子了。经过我再三思考后,还是先深入学习WinInet吧。
关于根据链接下载网页的各种方式在第一节已经介绍过了。这里再补充一下,还有一种方式是使用外部库libcurl,使用方便代码简洁,但我不把它当做我们主要学习的对象,因为它太过于简单。
这节可以说是个扩展篇,并不是这个项目优先考虑的内容。先介绍它主要是因为这部分东西更有意思,大家可能会更感兴趣。
目的
这个预处理是我自己勉强定义的,所以大家可能不理解。
通俗的说,URL预处理意为对一个URL链接本体进行处理,请大家不要误以为是对HTML网页内容进行分析。
再说清楚一些,获取链接所指向的内容前,程序并不知道这个内容是什么类型的。也就是说,它可能是一个HTML也可能是图片,又或者是一个CSS文件。所以我们要对URL进行一定的预处理,然后判断文件后缀之类的。
先给出本节流程图:
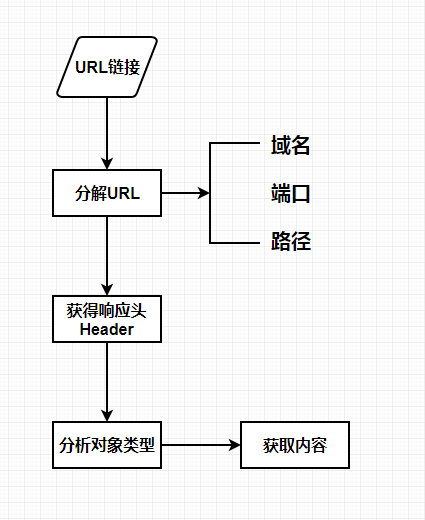
很多人可能不理解获得内容类型为什么需要先分解URL,那就接着往下看。
理论
从基础说起,大家都模糊地知道URL是什么,我给出它的定义:
URL是统一资源定位符(英语Uniform Resource Locator的缩写)也被称为网页地址,是因特网上标准的资源的地址。它最初是由蒂姆·伯纳斯·李发明用来作为万维网的地址。现在它已经被万维网联盟编制为互联网标准RFC1738了。
URL由多部分组成,详细说有9部分,我们一个一个介绍。有关资料部分来自于going_han的博客。
一个URL的实例: scheme://user:password@host:port/path;params?query#frag
| 编号 | 名称 | 介绍 |
|---|---|---|
| 1 | 协议(protocol) | 为进行网络中的数据交换而建立的规则、标准或约定。有时也叫scheme,常用的协议有http、https、ftp、file、mailto。 |
| 2 | 用户名(user) | 一般用不到,为访问资源使用的用户名。 |
| 3 | 密码(password) | 一般也用不到,为访问资源使用的密码。 |
| 4 | 域名(domain) | 域名(英语:Domain Name),简称域名、网域,是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。有时也叫host,可以使用IP地址作为域名使用。 |
| 5 | 端口(port) | 在网络技术中,端口(Port)有好几种意思。我们这里所指的端口不是指物理意义上的端口,而是特指TCP/IP协议中的端口,是逻辑意义上的端口。端口不是一个必须部分,如果省略将采用协议默认使用的端口。 |
| 6 | 路径(path) | 由零或多个“/”符号隔开的字符串,一般用来表示主机上的一个目录或文件地址。 |
| 7 | 参数(params) | 这是用于指定特殊参数的可选项。 |
| 8 | 查询(query) | 可选项。用于给动态网页传递参数,可有多个参数,用“&”符号隔开,每个参数的名和值用“=”符号隔开。 |
| 9 | 片段(frag) | 主要用于对资源进行分类。例如一个网页中有多个名词解释,可使用fragment直接定位到某一名词解释。访问一个帮助文档时,文档的各个章节就可以表述为片段。 |
所以分解URL有什么用呢?我们再简单了解一下HTTP访问的步骤,HTTP访问时会进行多步操作,其中有两步我想重点介绍一下,分别是:发送请求头(Request Headers)和接受响应头(Response Headers)。
其实大家现在就可以直观的了解它,介绍一种方法。
随便找一个可用网页(比如这篇博客) -> 点击键盘上的F12,弹出开发人员调试工具 -> 进入’Network’选项页 -> 点击录制按钮(黑色的圆点),按钮变红色 -> 刷新页面。
然后会有很多信息,我们要找的一般在第一个位置,Name一般为URL最后一个’/‘后的字符串。如果是在这篇博客进行的上述操作,则Name为’03-spiking3/‘,点击会显示详细信息。
我使用的浏览器效果如下图,部分进行了打码处理,URL为localhost是因为我在本地测试。
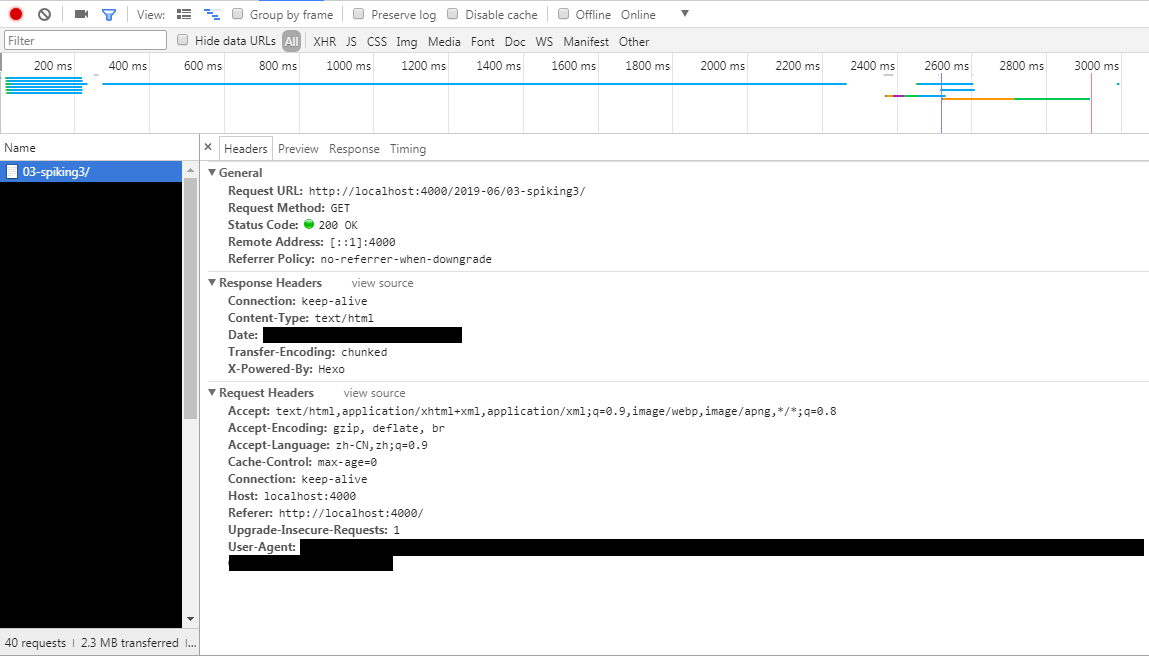
这里已经很直观了,我们需要的就是Response Headers中的’Content-Type:text/html’,这个可以用来判断内容的类型。大家可以再打开一个图片URL进行观察,比如上面那个截图,发现其中’Content-Type:image/png’。我们根据此信息来判断内容的类型。
其他信息大家可以自行了解,对项目作用不大,我就不作介绍了。
另外,本节含有大量string类的内容,但只要不是初学者都很熟悉了,因此不作理论上的介绍。
实战
这部分理论易理解,但代码部分比较长。先给出本节所有的代码:
1 | string _trim(const string &str) { |
_trim函数作用为去除字符串的空白换行符。
parse_url函数作用为分解URL,分解为端口、域名和路径。
judgeUrlType函数作用为获得HTTP响应头并分析URL内容类型。
string
本节使用C++STL中的string类比较多,简单的大家都使用过,所以介绍一下几个比较陌生的函数。
find_first_not_of
1 | size_t find_first_not_of (const string& str, size_t pos = 0) const; |
Return Value即返回值,返回第一个不匹配字符的位置,如果没有不匹配字符则返回string::npos。若使用字符串作参数,则此处不匹配字符指参数中不包含的字符。
string::npos
1 | static const size_t npos = -1; |
find_last_not_of
1 | size_t find_last_not_of (const string& str, size_t pos = npos) const; |
Return Value即返回值,与find_first_not_of类似,返回最后一个不匹配字符的位置。
substr
1 | string substr (size_t pos = 0, size_t len = npos) const; |
Return Value即返回值,返回从pos开始长度为len的子串。